合成控制法
合成控制法概述
在上面的讲解中,我们反复多次强调,随机实验中的“随机性”最为关键,因为它可以很好地识别出我们所要进行比较的“处理组”和“控制组”。一旦“处理组”和“控制组”的outcomes被我们观测到,我们就可以利用处理组的结果减去控制组的结果得到我们感兴趣的处理效应,例如产业政策效应。
但困难之处在于,实践中,我们往往只能观测到“处理组”的结果,而观测不到“如果处理组没有接受处理”的结果。这个时候,我们就需要去选择或“假象”一个或多个“控制组”(注:这里的假象,也是有理有据地假象。我们还有一个专业术语叫做“构造”)。
陈强老师说“选择控制组是一门艺术。确实,寻找适当的控制组(control group),即在各方面都与受干预地区相似却未受干预的其他地区,以作为处理组(treated group,即受到干预的地区)的反事实替身(counterfactuals)。但通常不易找到最理想的控制地区(control region),在各方面都接近于处理地区(treated region)。
比如,要考察仅在北京实施的某政策效果,自然会想到以上海作为控制地区;但上海毕竟与北京不完全相同。或可用其他一线城市(上海、广州、深圳)构成北京的控制组,比较上海、广州、深圳与北京在政策实施前后的差别,此方法也称“比较案例研究”(comparative case studies)。但如何选择控制组通常存在主观随意性(ambiguity),而上海、广州、深圳与北京的相似度也不尽相同。
因此,在上面一小节,我们简单介绍了匹配方法——通过能体现个体体征的协变量的相似度来构造出一个“控制地区”的结果。除了上述PSM方法之外,还有另一种构造“控制组”的方法——合成控制法(Synthetic Control Method)。
合成控制法是由Abadie and Gardeazabal (2003)提出来研究西班牙巴斯克地区(Basque country)恐怖活动的经济成本。其基本思想为:虽然无法找到巴斯克地区的最佳控制地区,但通常可对西班牙的若干大城市进行适当的线性组合,以构造一个更为贴切的“合成控制地区”(synthetic control region),并将“真实的巴斯克地区”与“合成的巴斯克地区”进行对比,故名“合成控制法”。合成控制法的一大优势是,可以根据数据(data-driven)来选择线性组合的最优权重,避免了研究者主观选择控制组的随意性。
合成控制法可以看做是DID的一类变种,因为它们有相同的基本设定:政策/干预在某一时点发生,但是只针对单个/少量个体。我们可以用政策实施前的观测数据来调整处理组和控制组之间的差异,然后来比较政策实施后,处理组和控制组如何演变。经过处理前数据调整过的处理组和控制组在政策实施后的差异就是政策的效应。但是,合成控制法与DID又存在一些差异:
与DID不同,处理组和控制组在政策实施前的差异调整并不是用回归方法来调整,而是用匹配法,但是又与PSM-DID不同,合成控制的匹配是为了消除政策实施前的差异,而不是解释处理的倾向性;
合成控制法依赖于较长的干预前时期;
匹配后,处理组合控制组应该基本已经消除了干预前的差异。通常,我们也需要包含结果变量来作为匹配变量;
统计显著性并不是由估计方法的抽样分布图来决定的,而是一种“随机推断”方式决定的——用安慰剂检验来估计一个原分布。
合成控制法的规定动作
单处理组
下面,我们用Abadie et al.(2010)的研究作为例子,来看看合成控制法的原理。作者们用合成控制法研究了美国加州香烟控制99法案对加州香烟消费的影响。为了限制香烟消费,1988年11月,加州政府通过了99法案,主要内容是将香烟消费税每包提高25美分,该法案1989年1月正式生效,作者主要考察这一政策对香烟消费的抑制作用到底有多大。由此,我们知道,香烟消费税在加州地区改变(提高)了,而在美国其他州并没有变化。因此,加州是“处理地区”,美国其他州是可能的“控制地区”。
此时,可能我们立马就能想起来,可以使用PSM呀。我们找出各个州的典型特征作为协变量,然后计算匹配得分,进行对比处理地区和匹配地区的香烟消费,得到香烟消费税提高的控烟效应。如果大家还记得上一节最后我们给出的PSM方法局限性——要求大样本。大家可能就会意识到:哎呀,PSM用在加州控烟税上可能有问题,因为这个样本中就只有加州和其他40多个州多年数据,这个样本似乎也不大。这种情况也是我们在写论文或者进行政策评估时经常会遇到的情况,所以用什么方法已经要深思熟虑。
我们接着来看加州控烟税的例子。为了避免其他州类似的政策对控制组产生影响,Abadie等剔除了研究期内出台相似控烟政策的州,最后潜在控制组里剩下38个州。也就是说样本包括美国39各州,1970-2000年的面板数据,变量包括:州年度人均香烟消费量、香烟平均零售价格、州人均收入对数、州人口结构(15-24岁比例)、州人均啤酒消费量等等。
记\(Y_{it}\)为地区i在t期实际观测到的结果变量,即香烟消费量。记\(Y_{it}^I\)的上标I表示地区i接受政策干预,即这个变量表示加州在提高香烟消费税后的香烟消费量。同理,\(Y_{it}^N\)的上标N表示没有受到政策干预。根据上文将的处理效应,我们实际上感兴趣的是:
\(ATE=Y_{it}^I-Y_{it}^N\)
现在的问题是,\(Y_{it}^N\)观测不到,因此,我们要估计出它。那么,怎么估计呢?即书本上的”因子模型“来估计\(Y_{it}^N\): \[\begin{equation} Y_{it}^N=\delta_t+\theta_tZ_i+\lambda_t\mu_i+\epsilon_{it} \end{equation}\]
(11)式右边第一项表示时间固定效应 (time fixed effects)。第二项表示可观测的向量(不受政策干预影响,也不随时间而变;比如,干预之前的预测变量之平均值),由于它对Y的效应随时间可变,因此,其系数\(\theta\)有时间下标。第三项表示不可观测的 “交互固定效应”(Interactive Fixed Effects),即个体固定效应\(\mu_i\)与时间固定效应\(\lambda_t\)的乘积(Bai, 2009)。第(4)项为随机扰动项。
我们咋一看,这不就是面板回归吗?但是请注意,第三项“交互固定效应”是不可观测的变量。这一点很重要。
第一步,构造一个“合成的加州”——它是美国其它州的加权平均,选择权重来使得“合成加州”与真实加州在控烟前几乎完全一样。虽然无法找到加州地区的最佳控制地区,但通常可对美国其他的若干州进行适当的线性组合,以构造一个更为贴切的“合成控制地区”(synthetic control region),并将“真实的加州地区”与“合成的加州地区”进行对比。也就是说,我们要利用其他州的线性组合来拟合出加州的\(Y_{it}^N\),线性组合就是每个州的Y前面乘以一个权重W之和,假设每个州的权重用\(w_j\)表示,那么,我们将线性组合表示为 \[\begin{equation} \sum_{j=1}^{j=N}w_jY_{jt}=\delta_t+\theta_t\sum_{j=1}^{j=N}w_jZ_j+\lambda_t\sum_{j=1}^{j=N}w_j\mu_j+\sum_{j=1}^{j=N}w_j\epsilon_{jt} \end{equation}\]
接下来,我们用(11)式减去(12)式: \[\begin{equation} Y_{it}^N-\sum_{j=1}^{j=N}w_jY_{jt}=\theta_t(Z_i-\sum_{j=1}^{j=N}w_jZ_j)+\lambda_t\sum_{j=1}^{j=N}(\mu_i-w_j\mu_j)+\sum_{j=1}^{j=N}(\epsilon_{it}w_j\epsilon_{jt}) \end{equation}\]
我们的目的是用其它38个州的线性组合\(\sum_{j=1}^{j=N}w_jY_{jt}\)来代替加州的\(Y_{it}^N\)。因此,我们想要\(Y_{it}^N-\sum_{j=1}^{j=N}w_jY_{jt}=0\)。那么,我们只要使得(13)式右边的第一个括号为0,第二个括号为0,那么整个(13)式的期望就等于0。此时,用\(\sum_{j=1}^{j=N}w_jY_{jt}\)合成的结果就是无偏的。但是,我们要注意,\(\mu_i\)是不可观测的变量,因此,\(\lambda_t\sum_{j=1}^{j=N}(\mu_i-w_j\mu_j)\)估计不出来,也即是说,上述估计行不通。
这怎么办呢?
我们仔细观察(13)式,里面可观测的变量有干预前的\(Y_{it}\)、\(Y_{jt}\)、\(Z_i\)、\(Z_j\),那么,我们只需要找到最优的权重\(w_j\)使得:
\(Y_{it}^N-\sum_{j=1}^{j=N}w_jY_{jt}=0,Z_i-\sum_{j=1}^{j=N}w_jZ_j=0\)
即根据可观测的经济特征与干预前结果变量所选择的合成控制 w,也会使得合成控制的不可观测特征接近于处理地区。反之,如果无法找到 w,使得合成控制能很好地复制(reproduce)处理地区的经济特征以及干预之前的结果变量,则不建议使用合成控制法。Abadie et al.(2010)已经证明了,当干预前的时期数趋向于无穷,那么,合成控制估计量就是无偏的。
小贴士:合成控制法对样本数据的要求为政策干预以前需要很多期数据,有人认为至少需要15年的数据,而政策干预后需要有5年以上的数据。同时地区最好超过10 个,但是又不会太多。最为重要的是,接受政策干预的地区个数极少。
第二步,计算反事实结果。用反事实结果变量与真实结果变量进行差分,这就是控烟的效应。
现在,我们定义\(D_{it}\)表示处理变量,合成控制方法假设可观测的结果\(Y_{it}\)等于处理效应\(\beta_{it}D_{it}\)与反事实结果\(Y_{it}^N\)之和: \[\begin{equation} Y_{it}=\beta_{it}D_{it}+\delta_t+\theta_tZ_i+\lambda_t\mu_i+\epsilon_{it} \end{equation}\]
处理效应\(\beta_{it}\)估计量就为处理后时期的处理组的可观测结果变量\(Y_{it}^I\)与合成控制组\(\sum_{i=2}^N w_i^* Y_{it}^N\)之差
\[\begin{equation} \hat{\beta}_{i1}=Y_{1t}-\sum_{i=2}^N w_i^* Y_{it} \end{equation}\]
Abadie, Diamond, and Hainmueller (2010)建议计算处理前和处理后时期的均方预测误差(MSPE)来作为合成控制估计法的推断统计量,步骤如下11.2.1节所示。即将所有安慰剂检验的MSPE和处理组的MSPE从大到小降序排列,就可以计算得到处理组在MSPE分布中的位置,换句话说,我们也可以将所有安慰剂中的处理效应和处理组的处理效应降序排列,构造出所有处理效应的分布函数\(\hat{p}_{it}=F(\hat{\beta}_{it})\),进而计算出处理组的处理效应的概率位置:
\[\hat{p}_{1t}=F(\hat{\beta}_{1t})\]
因为上述排序近似在组群间均匀分布,因为我们就可以判断处理组的位置\(\hat{p}_{1t}\)是否落入了均匀分布的尾部。例如,用5%的统计显著性水平,当\(\hat{p}_{1t}<0.025或者\hat{p}_{1t}>0.975\)时,我们都可以拒绝原假设——处理组的处理效应\(\hat{\beta}_{1t}=0\)。
第三步,评价统计显著性。
我们来继续看看加州控烟税政策的效果。
第一步,我们在stata中输入下列命令:
\(ssc~~install~~synth,~replace~~~\)(下载并安装synth程序)
其中,选择项 “replace” 表示如有此命令更新版本,可以新命令覆盖旧命令。
命令synth的基本句型为:
\(synth~~y~~x1~~x2~~x3 ,~~trunit(\#)~~trperiod(\#)~~counit(numlist)~~xperiod(numlist)~~mspeperiod()~~figure~~\\ resultsperiod()~~nested~~allopt~~keep(filename)\)
其中,“y” 为结果变量(outcome variable),“x1 x2 x3” 为预测变量(predictors)。
必选项 “trunit(#)” 用于指定处理地区(trunit 表示 treated unit)。
必选项 “trperiod(#)” 用于指定政策干预开始的时期(trperiod 表示 treated period)。
选择项 “counit(numlist)” 用于指定潜在的控制地区(即donor pool,其中 counit 表示 control units),默认为数据集中的除处理地区以外的所有地区。
选择项 “xperiod(numlist)” 用于指定将预测变量(predictors)进行平均的期间,默认为政策干预开始之前的所有时期(the entire pre-intervention period)。
选择项 “mspeperiod()” 用于指定最小化均方预测误差(MSPE)的时期,默认为政策干预开始之前的所有时期。
选择项 “figure” 表示将处理地区与合成控制的结果变量画时间趋势图,而选择项 “resultsperiod()” 用于指定此图的时间范围(默认为整个样本期间)。
选择项 “nested” 表示使用嵌套的数值方法寻找最优的合成控制(推荐使用此选项),这比默认方法更费时间,但可能更精确。在使用选择项 “nested” 时,如果再加上选择项 “allopt”(即 “nested allopt”),则比单独使用 “nested” 还要费时间,但精确度可能更高。
选择项 “keep(filename)” 将估计结果(比如,合成控制的权重、结果变量)存为另一Stata数据集(filename.dta),以便进行后续计算。更多选择项,详见help synth。
第二步,打开数据集之后,输入下列命令:
\(xtset~~state~~year\)(声明面板数据)
第三步,在stata中输入下列合成控制法估计命令:
\(synth~~cigsale~~retprice~~lnincome~~age15to24~~beer~~cigsale(1975)~~cigsale(1980)~~cigsale(1988),\\ ~~trunit(3)~~trperiod(1989)~~xperiod(1980(1)1988)~~ figure~~nested~~keep(smoking\_synth)\)
估计结果如下:
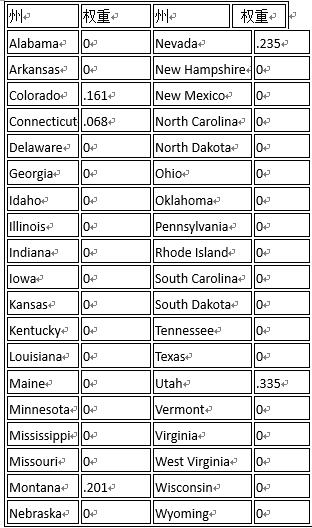
图6显示,大多数州的权重为0,而只有以下五个州的权重为正,即Colorado (0.161),Connecticut (0.068),Montana (0.201),Nevada (0.235)与Utah (0.335),此结果与Abadie et al. (2010)汇报的结果非常接近(细微差别或由于计算误差)。
下图显示了加州和其他38个州的合成结果:
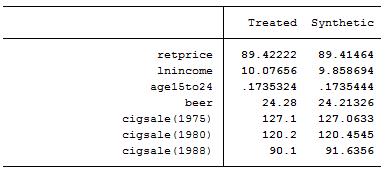
从图7可知,加州与合成加州的预测变量均十分接近,故合成加州可以很好地复制加州的经济特征。然后比较二者的人均香烟消费量在1989年前后的表现:
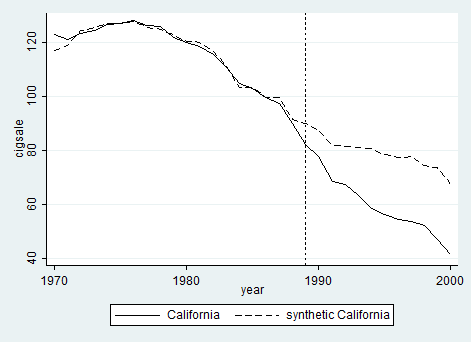
从上图可知,在1989年控烟法之前,合成加州的人均香烟消费与真实加州几乎如影相随,表明合成加州可以很好地作为加州如未控烟的反事实替身。在控烟法实施之后,加州与合成加州的人均香烟消费量即开始分岔,而且此效应越来越大。
更直观地,可打开另一Stata程序,调用已存的数据集smoking_synth.dta,计算加州与合成加州人均香烟消费之差(即处理效应),然后画图。
\(use~~smoking\_synth.dta,~~clear\)
(如不打开另一Stata程序,则此数据集将覆盖原有的数据集smoking.dta)
\(gen~~effect= \_Y\_treated - \_Y\_synthetic\)
(定义处理效应为变量effect,其中 “_Y_treated” 与 “_Y_synthetic” 分别表示处理地区与合成控制的结果变量)
\(label~~variable~~\_time "year"\)
\(label~~variable~~effect~~"gap~~in~~per-capita~~cigarette~~sales (in packs)"\)
(为了画图更漂亮,加上时间变量与处理效应的标签,可使用变量管理器(variable manager)来方便地加标签)
\(line~~effect~~\_time,~~xline(1989,~lp(dash))~~yline(0,lp(dash))\)
(画处理效应的时间趋势图,并在横轴1989年处与纵轴0处分别画虚线,结果见下图)
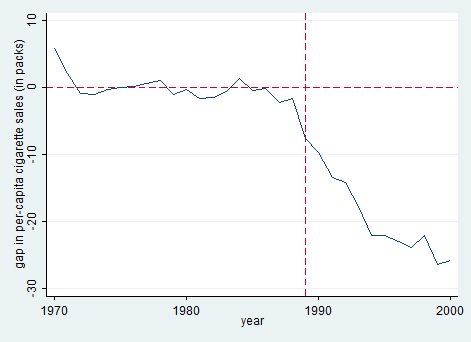
图9显示,加州控烟法对于人均香烟消费量有很大的负效应,而且此效应随着时间推移而变大。具体来说,在1989-2000年期间,加州的人均年香烟消费减少了20多包,大约下降了25%之多,故其经济效应十分显著(economically significant)。
到此,我们关心的合成控制法主要结果都呈现出来了。但是在使用合成控制法时,如何进行稳健性检验与统计推断?
为了检验上述合成控制估计结果的稳健性,Abadie et al. (2010)加入了更多的预测变量,比如失业率、收入不平等、贫困率、福利转移、犯罪率、毒品相关的逮捕率、香烟税、人口密度等;发现结果依然稳健。
另外一个担心是,地区之间无互相影响(no interference between units)的假定可能不满足,比如加州的反烟运动可能波及其他州,烟草行业或将其他州的香烟广告预算投入到加州,甚至从其他州走私便宜香烟到加州。Abadie et al. (2010)根据史实对此进行了探讨,认为这些效应均不大,至少不可能导致上文图中如此大的处理效应。
安慰剂检验
上述结果为对控烟法处理效应的点估计。此点估计是否在统计上显著(statistically significant)?Abadie et al. (2010)认为,在比较案例研究中,由于潜在的控制地区数目通常并不多,故不适合使用大样本理论进行统计推断。
为此,Abadie et al. (2010)提出使用“安慰剂检验”(placebo test)来进行统计检验,这种方法类似于统计学中的“排列检验”(permutation test),适用于任何样本容量。
“安慰剂”(placebo)一词来自医学上的随机实验,比如要检验某种新药的疗效。此时,可将参加实验的人群随机分为两组,其中一组为实验组,服用真药;而另一组为控制组,服用安慰剂(比如,无用的糖丸),并且不让参与者知道自己服用的究竟是真药还是安慰剂,以避免由于主观心理作用而影响实验效果,称为“安慰剂效应”(placebo effect)。
安慰剂检验借用了安慰剂的思想。具体到加州控烟法的案例,我们想知道,使用上述合成控制法所估计的控烟效应,是否完全由偶然因素所驱动?换言之,如果从donor pool随机抽取一个州(而不是加州)进行合成控制估计,能否得到类似的效应?
为此,Abadie et al. (2010)进行了一系列的安慰剂检验,依次将donor pool中的每个州作为假想的处理地区(假设也在1988年通过控烟法),而将加州作为控制地区对待,然后使用合成控制法估计其“控烟效应”,也称为“安慰剂效应”。通过这一系列的安慰剂检验,即可得到安慰剂效应的分布,并将加州的处理效应与之对比。
在此有个技术细节,即在对某个州进行安慰剂检验时,如果在“干预之前”其合成控制的拟合效果很差(均方预测误差MSPE很大),则有可能出现在“干预之后”的“效应”波动也很大,故结果不可信。类似地,如果合成加州在干预前对于加州的拟合很差,则我们也不会相信干预之后的合成控制估计结果。
注意事项
在使用合成控制法时,需要特别注意一下几点:
1、我们是将没有实行政策的地区作为备选的合成控制组,但是如果i地区实施政策对j地区也产生了影响,那么,这个时候,我们就应该将j地区从备选控制组中提出掉,例如加州提高控烟税,对威斯康辛州有很大影响,那么,我们就应该将威斯康辛州从38个备选里去掉;
2、如果在研究期间,有一些地区受到非常大的特殊冲击,那么,这时候我们也要将其剔除;
3、尽量使得控制地区与处理地区具有相似的特征;
4、合成控制法对样本数据的要求为政策干预以前需要很多期数据,有人认为至少需要15年的数据,而政策干预后需要有5年以上的数据。同时地区最好超过10 个,但是又不会太多。最为重要的是,接受政策干预的地区个数极少。
5、如果政策冲击的效应需要一段时间才会显现(滞后效应),则也要求干预后的期数足够大。
多处理组
均值估计量与安慰剂推断
在多处理组情形下,例如,处理组用下标e=1,……,E表示,那么,加总每个时期处理效应的一个自然的方式就是加权平均每个处理个体的处理效应
\[\beta_{t}=\frac{\sum_{e=1}^E \hat{\beta}_{et}}{E}\]
其中,\(\beta_{t}\)表示处理后的某个时期t的堆叠处理处理效应——处理组的平均处理效应。此外,我们还可以计算中位数处理效应,以及Hodges-Lehmann(1962)估计量。
同理,我们也可以构造一个检验估计量\(p_t\)来进行多处理个体情形下的统计推断,即\(p_t\)等于单个处理个体检验统计量\(\hat{p}_{et}\)的均值:
\[p_{t}=\frac{\sum_{e=1}^E \hat{p}_{et}}{E}\]
这种堆叠推断方法有一些优势:第一,是Abadie et al.(2010)推断的一般化;第二,均值排序有已知的分布函数,可以进行精确的推断,而不依赖于大样本性质,从而避免了统计量分布的经验估计;第三,均值排序可以减小奇异值的影响;第四,排序总和检验可以减轻处理个体间的处理效应异质性的影响,例如Wilcoxon(1945)排序总和检验。
但是这个统计检验与推断的缺点是:我们检验的是每个处理效应为零的原假设,而不是平均处理效应等于零的原假设。
HL估计量与置信区间
为了解决上述统计检验与推断的缺点,我们可以使用Hodges-Lehmann(1962)估计量(下文成HL估计量)及对异质性处理效应的检验。如11.2.1节所述,对单一处理个体的处理效应\(\hat{\beta}{1t}\),我们使用百分位排序\(\hat{p}_{1t}=F(\hat{\beta}_{1t})\)作为一个检验统计量,来进行统计显著性推断:当\(0.025 \leq F(\hat{\beta}_{1t}) \leq 0.975\)时,我们可以在5%的显著性水平上拒绝原假设——处理效应为0。
我们可以逆向思维来求解上述过程,即有一个数\(\tau\),我们求解\(\tau\)的值为多少时,下式成立:
\[0.025 \leq F(\hat{\beta}_{1t}-\tau) \leq 0.975\]
其中,\(F(\hat{\beta}_{1t}-\tau)\)表示调整后的排序,HL估计量就是\(\tau\)的估计值,它给出了当处理效应估计量减去该值时拒绝原假设的统计量,而95%的置信区间就是不拒绝上式的\(\tau\)的集合。
为了构造多处理个体堆叠处理效应的置信区间,我们也可以同理来进行平均排序统计量\(p_t\)的逆向求解。也就是说,我们找到一个量\(\tau\),首先对所有处理个体计算\(\hat{\beta}_{et}-\tau\),然后重新计算对应的\(F(\hat{\beta}_{et}-\tau)\)。定义平均调整排序为:
\[p(\tau)=\frac{\sum_e F(\hat{\beta}_e-\tau)}{E}\]
95%置信区间就是,\(\tau\)的值使得平均调整排序\(p(\tau)\)落在下列区间:
\[0.025 \leq \frac{1}{E} \sum_{e=1}^E F(\hat{\beta}_{et}-\tau) \leq 0.975\]
然后,压缩置信区间,我们就可以得到HL点估计量。HL点估计量仅仅是置信区间上下界的均值6。
在单一处理个体情形下,处理效应估计量均值、中位数和HL估计量是相同的,置信区间也是相同的。但在多处理个体情形下,处理效应均值、中位数和HL估计量并不相同,对应的置信区间也不相同。当存在个体处理效应异质性的时候,某些个体的极端处理效应估计量会严重影响到处理效应的均值估计量,此时,传统的均值估计量和HL估计量,及其对应的置信区间就会存在较大差异。虽然均值估计量更易于理解,但是HL估计量对个体处理效应异质性更加稳健(Dube and Zipperer,2015;Gobillon and Magnac, 2016;Isaksen,2020)。
下面,我们来看两个例子及其stata应用。一个是来自于Dube and Zipperer(2016)、Powell(2021,JBES)的最低工资调整对劳动力市场的影响;另一个是Isaksen(2020,JEEM)的国际控制污染协议的减排效应。
偏误纠正
合成控制法的最新进展:合成控制法与DID的结合
广义合成控制法
矩阵完成法
合成DID
合成控制预测区间scpi
Cattaneo, Feng, Palomba and Titiunik (2022): scpi: Uncertainty Quantification for Synthetic Control Estimators. Working paper.
Cattaneo, Feng, Palomba and Titiunik (2022): Uncertainty Quantification in Synthetic Controls with Staggered Treatment Adoption. Working paper (coming soon).
Cattaneo, Feng and Titiunik (2021): Prediction Intervals for Synthetic Control Methods. Journal of the American Statistical Association 116(536): 1865-1880.
克服计量方法选择困难症
DID与PSM
我曾经看过一个最简单的描述:
DID是比较四个点,Treated before, treated after; control before, control after;
Matching是比较两个点:Treated, control;
DID+Matching是用matching的方法来确定treated和control。
断点回归
1、断点回归最大的优势就是在断点附近接近随机实验,也就是说,断点回归可以认为是一种“局部随机实验”;
2、但是,正因为断点回归只在断点附近随机性强,因此,仅能推断断点处的因果关系,不一定能推广到其他样本,也就是说结论在理论上的一般性存疑。
合成控制法与DID
首先,根据Abadie et al. (2010)的因子模型(factor model),合成控制法对双向固定效应模型作了推广。具体来说,双重差分法仅允许个体固定效应与个体时间效应以相加(additive)的形式存在,隐含假设所有个体的时间趋势都相同(parallel trend assumption);而合成控制法的因子模型,则允许 “互动固定效应”(interactive fixed effects),即可以存在多维的共同冲击(common shocks),而每位个体对于共同冲击的反应(factor loading)可以不同,故允许不同个体有不同的时间趋势。
其次,Abadie et al. (2015)指出,回归法也可以视为对控制地区作了线性组合,且权重之和也为1;而不同之处在于,合成控制法的权重必须非负,但回归法的权重可能出现负值,即出现过分外推(extrapolation)而离开了样本数据的取值范围(support of the data)。比如,在跨国研究中,将很不相同的国家放在一起进行回归,就可能出现过分外推,而导致 “外推偏差”(extrapolation bias)。由于合成控制法的权重必须非负,故避免了过分外推。